Pseudo R-square : Understanding Goodness-of-Fit in Logistic Regression
Logistic regression doesn’t use traditional R-squ. like linear regression because binary outcomes require a different approach to measure goodness-of-fit. This blog explores Pseudo R-squ., including McFadden’s, Cox & Snell’s, and Nagelkerke’s metrics, and how they help evaluate logistic regression models effectively.
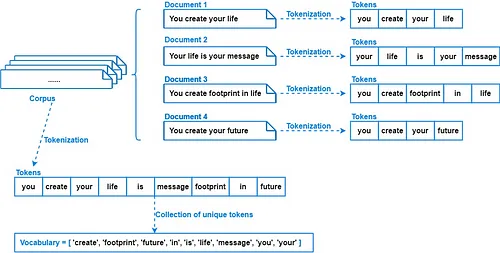
NLP 101: Text Prepocessing 1 - Tokenization
This blog provides a comprehensive overview of key text preprocessing techniques like tokenization, lemmatization, stemming, stop-word removal, and handling punctuation. It also highlights their importance, practical applications, and limitations, setting a strong foundation for efficient natural language processing workflows.
NLP 201: Text Prepocessing 2 - Vectorization
This blog breaks down essential methods for converting text into numerical representations for machine learning. It also covers One-Hot Encoding (OHE), Bag of Words (BoW), and TF-IDF, explaining their principles, use cases, and limitations. With clear examples and insights, it serves as a practical guide for building effective NLP models.
